
Decoupling Time and Risk: Risk-Sensitive RL with General Discounting
Published:
In standard Reinforcement Learning (RL), the discount factor (\(\gamma\)) is often treated as a fixed parameter of the Markov Decision Process or a tunable hyperparameter for training stability. We typically default to exponential discounting, where the value of a reward decays by a constant factor at every time step.
While mathematically convenient, this standard formulation is restrictive. It limits our ability to model complex time preferences (how an agent values the future vs. the present) and risk preferences (how an agent handles uncertainty) independently.
In our recent paper, “Decoupling Time and Risk: Risk-Sensitive RL with General Discounting,” we propose a unified framework that supports general discount functions and risk measures. By properly handling time consistency and tracking accumulated rewards, we show that we can capture more expressive behaviors, like preference reversals, and significantly improve performance in complex environments.
The Problem with “Stationary” Hyperbolic Discounting
A major motivation for this work was to revisit hyperbolic discounting. Unlike exponential discounting, hyperbolic discounting models agents that are impatient in the short term but patient in the long term—a behavior observed in humans and animals.
A notable approach by Fedus et al. (2019) attempted to introduce hyperbolic discounting into Deep RL. They approximated the hyperbolic discount function as a weighted average of multiple exponential discount factors \(\gamma_i\):
\[Q_{\text{hyperbolic}}(s,a) \approx \sum_{i} w_i Q_{\gamma_i}(s,a)\]However, there is a theoretical issue here. Fedus et al. used fixed weights \(w_i\) throughout the episode. By enforcing a stationary policy (one that acts the same way regardless of time), they implicitly reset the agent’s “time zero” at every step. This leads to time inconsistency: the policy the agent plans at \(t=0\) is not the policy it wants to execute at \(t=1\). The agent is effectively fighting its future selves.
Our Solution: Time-Dependent Weights
We argue that to solve general discounting problems correctly, the agent must be explicitly aware of time, and the weights must evolve.
In our multi-horizon framework, we show that as time \(t\) progresses, the effective contribution of each exponential discount factor \(\gamma_i\) changes. The weights should not be static constants \(w_i\), but rather time-dependent weights \(w_{i,t}\):
\[w_{i,t} \propto w_i \gamma_i^t\]Because these weights vary with time, the decision problem becomes non-stationary. To handle this, our agent learns a set of distributional value functions for different \(\gamma_i\)’s, but combines them dynamically based on the current time step \(t\).
This formulation is theoretically coherent and finds the true optimal non-stationary policy that maximizes the objective defined at the start of the episode.
A Unified Framework for Time and Risk
Our contributions go beyond just fixing hyperbolic discounting. We introduce a broad framework called RIGOR (RIsk-sensitive RL under General discounting Of Returns) that decouples time and risk:
- Stock-Augmented Distributional RL: We build on the idea of augmenting the state with a “stock” \(c\) that tracks accumulated rewards. We derive an “Anytime Proxy” equation that guarantees the agent optimizes the global objective from any time \(t\): \(C^d_0 + G^d_0 \overset{D}{=} d_t \left( C^d_t + G^d_t \right)\)
- General Discount Functions: Our method supports any non-increasing discount function (hyperbolic, quasi-hyperbolic, etc.), not just exponential.
- OCE Risk Measures: By operating on the full return distribution, we can optimize for Optimized Certainty Equivalent (OCE) risk measures, such as Conditional Value at Risk (CVaR) or Entropic Risk.
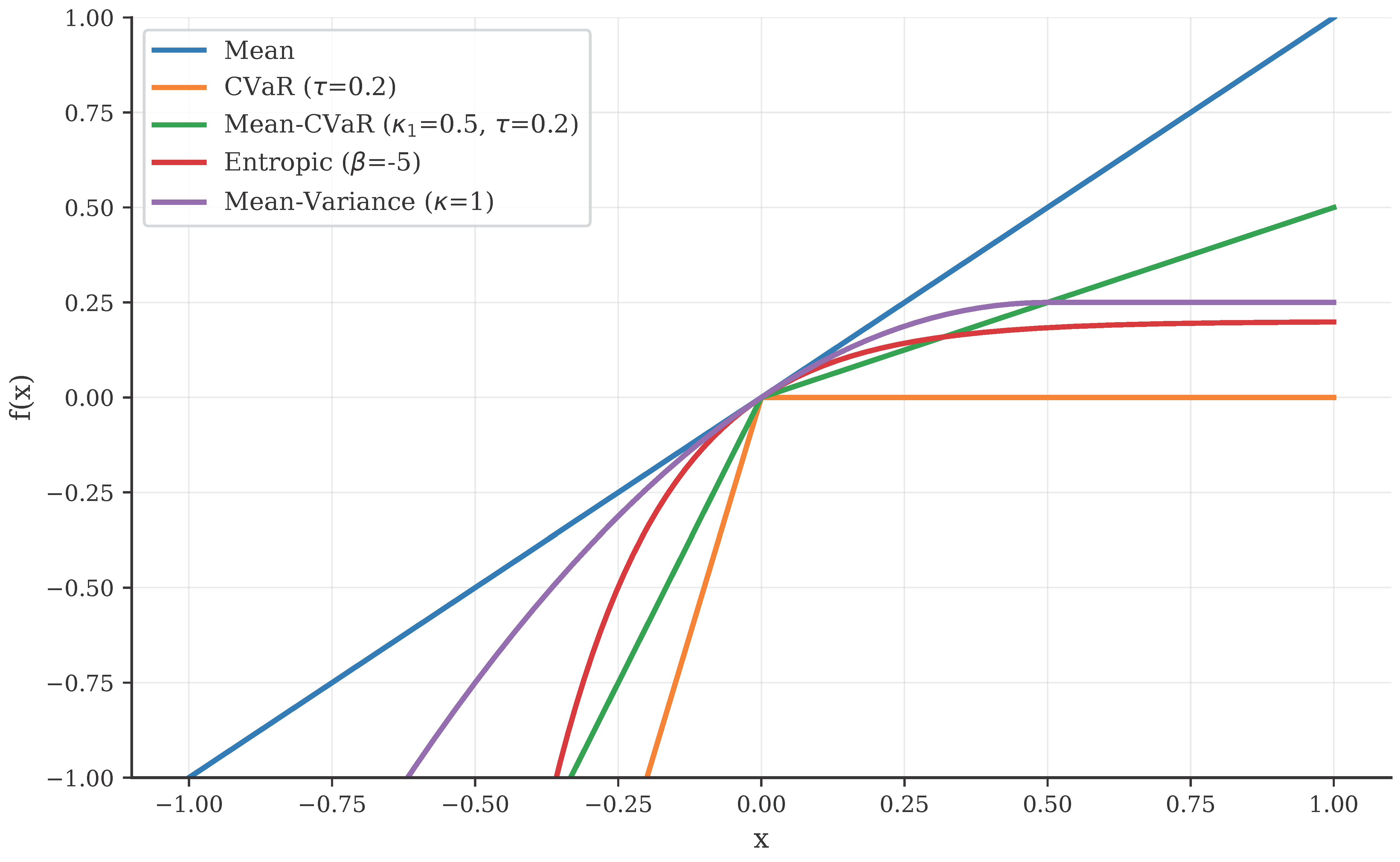 Utility functions for common OCE risk measures. Our framework allows us to plug in different utility functions \(f\) to shape the agent’s risk profile, independent of the discount function.
Utility functions for common OCE risk measures. Our framework allows us to plug in different utility functions \(f\) to shape the agent’s risk profile, independent of the discount function.
Preference Reversals in Wealth Management
To demonstrate that our agent captures human-like time preferences, we tested it on a “Goal-Based Wealth Management” problem. We compared a standard Exponential agent against our Hyperbolic agent.
The results showed a clear preference reversal. When the “late goal” (stars) was more valuable, the Hyperbolic agent (red) showed impatience for immediate rewards but patience for distant ones, shifting its probability of success in a way the Exponential agent (blue) could not capture.
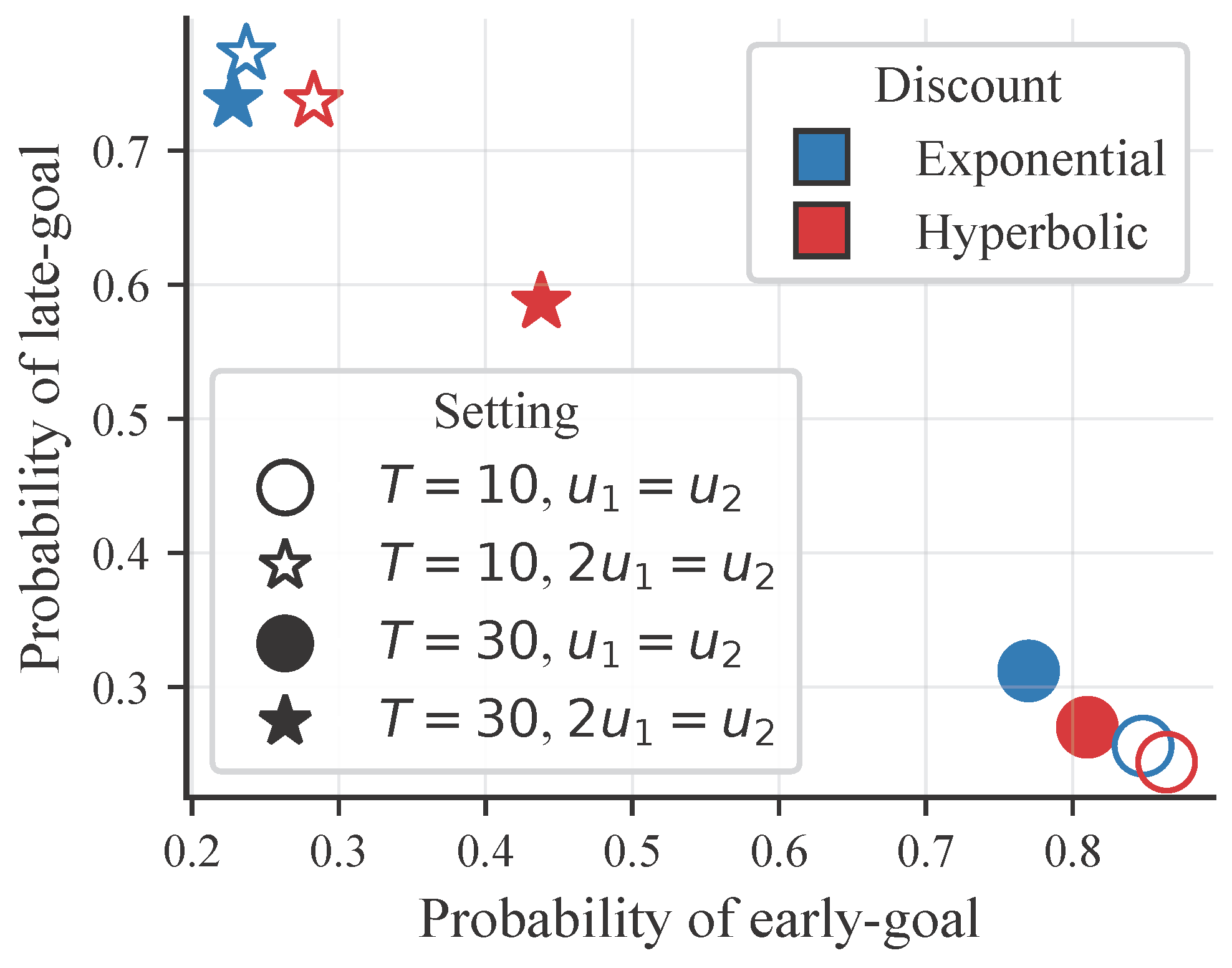 Monte-Carlo probabilities of achieving goals. The shift in the red markers (Hyperbolic) compared to the blue (Exponential) illustrates the agent’s non-linear time preference, capturing behaviors that standard RL misses.
Monte-Carlo probabilities of achieving goals. The shift in the red markers (Hyperbolic) compared to the blue (Exponential) illustrates the agent’s non-linear time preference, capturing behaviors that standard RL misses.
Improving Performance in Atari
Finally, we evaluated whether fixing the theoretical inconsistency in Fedus et al. actually matters for performance. We compared our Time-Consistent agent against the Time-Inconsistent baseline across 50 Atari games.
The results were significant. By correctly modeling the non-stationary optimal policy and evolving the weights \(w_{i,t}\) over time, our method achieved higher returns in 39 out of 50 games, with a mean improvement of roughly 40%.
 Relative performance improvement of our Time-Consistent algorithm across 50 Atari games. The consistent positive trend demonstrates the benefits of maintaining time-consistency under hyperbolic discounting.
Relative performance improvement of our Time-Consistent algorithm across 50 Atari games. The consistent positive trend demonstrates the benefits of maintaining time-consistency under hyperbolic discounting.
Conclusion
Discounting is a fundamental part of the problem definition. It encodes time preference, which is distinct from the risk preference encoded in the objective function.
By decoupling these two dimensions and ensuring our optimization remains time-consistent, we can build RL agents that are not only more expressive and robust but also perform better on complex control tasks.
For the full theoretical analysis, performance bounds, and proofs, please check out the paper.
References
Fedus, W., Gelada, C., Bengio, Y., Bellemare, M. G., and Larochelle, H. Hyperbolic Discounting and Learning over Multiple Horizons. arXiv preprint.